您现在的位置是: 首页 > 系统推荐 系统推荐
序列号生成器有用吗_序列号生成器怎么用
ysladmin 2024-05-24 人已围观
简介序列号生成器有用吗_序列号生成器怎么用 大家好,今天我想和大家分享一下我对“序列号生成器有用吗”的理解。为了让大家更深入地了解这个问题,我将相关资料进行了整理,现在就让我们一起来探讨吧。1.windows11系
大家好,今天我想和大家分享一下我对“序列号生成器有用吗”的理解。为了让大家更深入地了解这个问题,我将相关资料进行了整理,现在就让我们一起来探讨吧。
1.windows11系统怎样盗版AE
2.序列号生成器原理
3.OpenIM转载万亿级调用系统:微信序列号生成器架构设计及演变
4.电脑cpu序列号生成有什么规则
5.红色警戒3命令与征服 联机 cd key重复怎么办
windows11系统怎样盗版AE
需要下载好AE破解版安装包。
第一步,在安装之前,首先找到hosts文件,该文件详细位置是C:\windows\system32\drivers\etc\hosts。找到后用记事本打开hosts文件,把下列网址复制上去。网址在下载好的安装包里面有。
第二步,找到下载好的安装包,打开“AECS4原版”这个文件夹,找到安装程序setup,点击安装即可。
第三步,进入安装程序后,选择试用,这样不用输入序列号就可以安装。
第四步,点击下一步,开始选择安装语言,最好是英语,默认就是English。
第五步,选择安装位置,默认情况下是安装在C盘的,但AE文件较大,最好别安装在C盘,一般都是安装到D盘里。
第六步,安装好之后,点击开始找到AE打开。
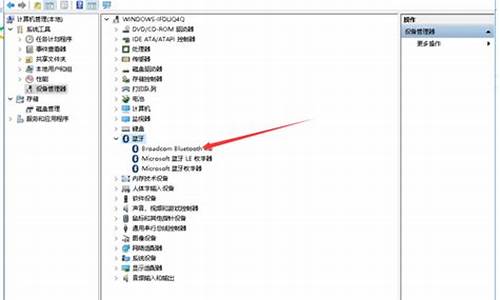
第七步,打开后会出现如下对话框,要输入的序列号用序列号生成器生成,序列号生成器在下图“注册破解”文件夹里可以找到。
第八步,打开注册破解器,如下图点击下面的按钮就可以生成两行序列号,选择上面那行,复制然后粘贴即可。
第九步,安装完成,点击OK按钮即可。
AE全称AfterEffects,是由世界著名的图形设计、出版和成像软件设计公司AdobeSystemsInc开发的专业非线性特效合成软件。是一个灵活的基于层的2D和3D后期合成软件,包含了上百种特效及预置动画效果,与同为Adobe公司出品的Premiere,Photoshop,Illustrator等软件可以无缝结合,创建无与伦比的效果。
序列号生成器原理
楼上的在扯淡。。。。。。你要重新用算号器算个新的才可以。。。。算前记得断网。。然后你玩游戏的时候也记得断网。。。否则第4章开始前还要输一次(内牛满面啊)。。。。还有就算你断网算号器也不一定会一次成功。。多试验几次
OpenIM转载万亿级调用系统:微信序列号生成器架构设计及演变
破解软件。
找到软件生成序列号的算法。
根据序列号的算法生成序列号。
序列号可能有很多,就想解方程一样,有多个解,有时候跟机器相关。
对不同的软件序列号的算法是不一样的。
算法是你破解出来的。比较简单的可以这样做:
将EXE文件反汇编一下,
找到关键跳转:
跟如程序;
可能有一个比较语句;
后面的值可能就是序列号。
如果是的话,用一个专门的序列号生成器制作软件写入跳转的地址(要自己找,具体的就不说了。),和序列号等信息。
然后做一个序列号生成器。
安装的时候,提示注册,任意输入一个号码,运行序列号生成器,它会把相应的序列号写入内存,就可以了(跳转到正确地址)。
这个是最简单的,如果你有编程基础(特别是汇编),很快就能学会。我就是这么学的。好奇而已。不做这个。
复杂的就有相应的算法了,要仔细分析,很麻烦的。
有下去找网站学。比如 黑客基地 。
电脑cpu序列号生成有什么规则
微信在立项之初,就已确立了利用数据版本号实现终端与后台的数据增量同步机制,确保发消息时消息可靠送达对方手机,避免了大量潜在的家庭纠纷。时至今日,微信已经走过第五个年头,这套同步机制仍然在消息收发、朋友圈通知、好友数据更新等需要数据同步的地方发挥着核心的作用。
而在这同步机制的背后,需要一个高可用、高可靠的序列号生成器来产生同步数据用的版本号。这个序列号生成器我们称之为seqsvr,目前已经发展为一个每天万亿级调用的重量级系统,其中每次申请序列号平时调用耗时1ms,99.9%的调用耗时小于3ms,服务部署于数百台4核CPU服务器上。 本文会重点介绍seqsvr的架构核心思想,以及seqsvr随着业务量快速上涨所做的架构演变。
微信服务器端为每一份需要与客户端同步的数据(例如消息)都会赋予一个唯一的、递增的序列号(后文称为sequence),作为这份数据的版本号。 在客户端与服务器端同步的时候,客户端会带上已经同步下去数据的最大版本号,后台会根据客户端最大版本号与服务器端的最大版本号,计算出需要同步的增量数据,返回给客户端。这样不仅保证了客户端与服务器端的数据同步的可靠性,同时也大幅减少了同步时的冗余数据。
这里不用乐观锁机制来生成版本号,而是使用了一个独立的seqsvr来处理序列号操作,一方面因为业务有大量的sequence查询需求——查询已经分配出去的最后一个sequence,而基于seqsvr的查询操作可以做到非常轻量级,避免对存储层的大量IO查询操作;另一方面微信用户的不同种类的数据存在不同的Key-Value系统中,使用统一的序列号有助于避免重复开发,同时业务逻辑可以很方便地判断一个用户的各类数据是否有更新。
从seqsvr申请的、用作数据版本号的sequence,具有两种基本的性质:
举个例子,小明当前申请的sequence为100,那么他下一次申请的sequence,可能为101,也可能是110,总之一定大于之前申请的100。而小红呢,她的sequence与小明的sequence是独立开的,假如她当前申请到的sequence为50,然后期间不管小明申请多少次sequence怎么折腾,都不会影响到她下一次申请到的值(很可能是51)。
这里用了每个用户独立的64位sequence的体系,而不是用一个全局的64位(或更高位)sequence,很大原因是全局唯一的sequence会有非常严重的申请互斥问题,不容易去实现一个高性能高可靠的架构。对微信业务来说,每个用户独立的64位sequence空间已经满足业务要求。
目前sequence用在终端与后台的数据同步外,同时也广泛用于微信后台逻辑层的基础数据一致性cache中,大幅减少逻辑层对存储层的访问。虽然一个用于终端——后台数据同步,一个用于后台cache的一致性保证,场景大不相同。
但我们仔细分析就会发现,两个场景都是利用sequence可靠递增的性质来实现数据的一致性保证,这就要求我们的seqsvr保证分配出去的sequence是稳定递增的,一旦出现回退必然导致各种数据错乱、消息消失;另外,这两个场景都非常普遍,我们在使用微信的时候会不知不觉地对应到这两个场景:小明给小红发消息、小红拉黑小明、小明发一条失恋状态的朋友圈,一次简单的分手背后可能申请了无数次sequence。
微信目前拥有数亿的活跃用户,每时每刻都会有海量sequence申请,这对seqsvr的设计也是个极大的挑战。那么,既要sequence可靠递增,又要能顶住海量的访问,要如何设计seqsvr的架构?我们先从seqsvr的架构原型说起。
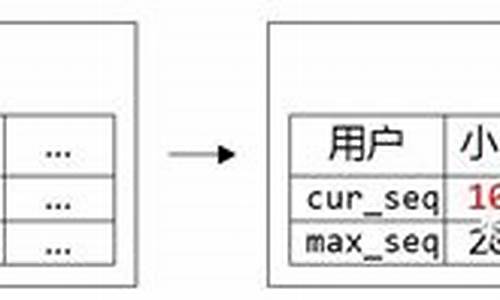
不考虑seqsvr的具体架构的话,它应该是一个巨大的64位数组,而我们每一个微信用户,都在这个大数组里独占一格8bytes的空间,这个格子就放着用户已经分配出去的最后一个sequence:cur_seq。每个用户来申请sequence的时候,只需要将用户的cur_seq+=1,保存回数组,并返回给用户。
预分配中间层
任何一件看起来很简单的事,在海量的访问量下都会变得不简单。前文提到,seqsvr需要保证分配出去的sequence递增(数据可靠),还需要满足海量的访问量(每天接近万亿级别的访问)。满足数据可靠的话,我们很容易想到把数据持久化到硬盘,但是按照目前每秒千万级的访问量(~10^7 QPS),基本没有任何硬盘系统能扛住。
后台架构设计很多时候是一门关于权衡的哲学,针对不同的场景去考虑能不能降低某方面的要求,以换取其它方面的提升。仔细考虑我们的需求,我们只要求递增,并没有要求连续,也就是说出现一大段跳跃是允许的(例如分配出的sequence序列:1,2,3,10,100,101)。于是我们实现了一个简单优雅的策略:
请求带来的硬盘IO问题解决了,可以支持服务平稳运行,但该模型还是存在一个问题:重启时要读取大量的max_seq数据加载到内存中。
我们可以简单计算下,以目前uid(用户唯一ID)上限2^32个、一个max_seq 8bytes的空间,数据大小一共为32GB,从硬盘加载需要不少时间。另一方面,出于数据可靠性的考虑,必然需要一个可靠存储系统来保存max_seq数据,重启时通过网络从该可靠存储系统加载数据。如果max_seq数据过大的话,会导致重启时在数据传输花费大量时间,造成一段时间不可服务。
为了解决这个问题,我们引入号段Section的概念,uid相邻的一段用户属于一个号段,而同个号段内的用户共享一个max_seq,这样大幅减少了max_seq数据的大小,同时也降低了IO次数。
目前seqsvr一个Section包含10万个uid,max_seq数据只有300+KB,为我们实现从可靠存储系统读取max_seq数据重启打下基础。
工程实现
工程实现在上面两个策略上做了一些调整,主要是出于数据可靠性及灾难隔离考虑
接下来我们会介绍seqsvr的容灾架构。我们知道,后台系统绝大部分情况下并没有一种唯一的、完美的解决方案,同样的需求在不同的环境背景下甚至有可能演化出两种截然不同的架构。既然架构是多变的,那纯粹讲架构的意义并不是特别大,期间也会讲下seqsvr容灾设计时的一些思考和权衡,希望对大家有所帮助。
seqsvr的容灾模型在五年中进行过一次比较大的重构,提升了可用性、机器利用率等方面。其中不管是重构前还是重构后的架构,seqsvr一直遵循着两条架构设计原则:
这两点都是基于seqsvr可靠性考虑的,毕竟seqsvr是一个与整个微信服务端正常运行息息相关的模块。按照我们对这个世界的认识,系统的复杂度往往是跟可靠性成反比的,想得到一个可靠的系统一个关键点就是要把它做简单。相信大家身边都有一些这样的例子,设计方案里有很多高大上、复杂的东西,同时也总能看到他们在默默地填一些高大上的坑。当然简单的系统不意味着粗制滥造,我们要做的是理出最核心的点,然后在满足这些核心点的基础上,针对性地提出一个足够简单的解决方案。
那么,seqsvr最核心的点是什么呢?每个uid的sequence申请要递增不回退。这里我们发现,如果seqsvr满足这么一个约束:任意时刻任意uid有且仅有一台AllocSvr提供服务,就可以比较容易地实现sequence递增不回退的要求。
但也由于这个约束,多台AllocSvr同时服务同一个号段的多主机模型在这里就不适用了。我们只能采用单点服务的模式,当某台AllocSvr发生服务不可用时,将该机服务的uid段切换到其它机器来实现容灾。这里需要引入一个仲裁服务,探测AllocSvr的服务状态,决定每个uid段由哪台AllocSvr加载。出于可靠性的考虑,仲裁模块并不直接操作AllocSvr,而是将加载配置写到StoreSvr持久化,然后AllocSvr定期访问StoreSvr读取最新的加载配置,决定自己的加载状态
同时,为了避免失联AllocSvr提供错误的服务,返回脏数据,AllocSvr需要跟StoreSvr保持租约。这个租约机制由以下两个条件组成:
这两个条件保证了切换时,新AllocSvr肯定在旧AllocSvr下线后才开始提供服务。但这种租约机制也会造成切换的号段存在小段时间的不可服务,不过由于微信后台逻辑层存在重试机制及异步重试队列,小段时间的不可服务是用户无感知的,而且出现租约失效、切换是小概率事件,整体上是可以接受的。
到此讲了AllocSvr容灾切换的基本原理,接下来会介绍整个seqsvr架构容灾架构的演变
最初版本的seqsvr采用了主机+冷备机容灾模式:全量的uid空间均匀分成N个Section,连续的若干个Section组成了一个Set,每个Set都有一主一备两台AllocSvr。正常情况下只有主机提供服务;在主机出故障时,仲裁服务切换主备,原来的主机下线变成备机,原备机变成主机后加载uid号段提供服务。
可能看到前文的叙述,有些同学已经想到这种容灾架构。一主机一备机的模型设计简单,并且具有不错的可用性——毕竟主备两台机器同时不可用的概率极低,相信很多后台系统也采用了类似的容灾策略。
主备容灾存在一些明显的缺陷,比如备机闲置导致有一半的空闲机器;比如主备切换的时候,备机在瞬间要接受主机所有的请求,容易导致备机过载。既然一主一备容灾存在这样的问题,为什么一开始还要采用这种容灾模型?事实上,架构的选择往往跟当时的背景有关,seqsvr诞生于微信发展初期,也正是微信快速扩张的时候,选择一主一备容灾模型是出于以下的考虑:
前两点好懂,人力、机器都不如时间宝贵。而第三点比较有意思,下面展开讲下
微信后台绝大部分模块使用了一个自研的RPC框架,seqsvr也不例外。在这个RPC框架里,调用端读取本地机器的client配置文件,决定去哪台服务端调用。这种模型对于无状态的服务端,是很好用的,也很方便实现容灾。我们可以在client配置文件里面写“对于号段x,可以去SvrA、SvrB、SvrC三台机器的任意一台访问”,实现三主机容灾。
但在seqsvr里,AllocSvr是预分配中间层,并不是无状态的。而前面我们提到,AllocSvr加载哪些uid号段,是由保存在StoreSvr的加载配置决定的。那么这时候就尴尬了,业务想要申请某个uid的sequence,Client端其实并不清楚具体去哪台AllocSvr访问,client配置文件只会跟它说“AllocSvrA、AllocSvrB…这堆机器的某一台会有你想要的sequence”。换句话讲,原来负责提供服务的AllocSvrA故障,仲裁服务决定由AllocSvrC来替代AllocSvrA提供服务,Client要如何获知这个路由信息的变更?
这时候假如我们的AllocSvr采用了主备容灾模型的话,事情就变得简单多了。我们可以在client配置文件里写:对于某个uid号段,要么是AllocSvrA加载,要么是AllocSvrB加载。Client端发起请求时,尽管Client端并不清楚AllocSvrA和AllocSvrB哪一台真正加载了目标uid号段,但是Client端可以先尝试给其中任意一台AllocSvr发请求,就算这次请求了错误的AllocSvr,那么就知道另外一台是正确的AllocSvr,再发起一次请求即可。
也就是说,对于主备容灾模型,最多也只会浪费一次的试探请求来确定AllocSvr的服务状态,额外消耗少,编码也简单。可是,如果Svr端采用了其它复杂的容灾策略,那么基于静态配置的框架就很难去确定Svr端的服务状态:Svr发生状态变更,Client端无法确定应该向哪台Svr发起请求。这也是为什么一开始选择了主备容灾的原因之一。
在我们的实际运营中,容灾1.0架构存在两个重大的不足:
在主备容灾中,Client和AllocSvr需要使用完全一致的配置文件。变更这个配置文件的时候,由于无法实现在同一时间更新给所有的Client和AllocSvr,因此需要非常复杂的人工操作来保证变更的正确性(包括需要使用iptables来做请求转发,具体的详情这里不做展开)。
对于第二个问题,常见的方法是用一致性Hash算法替代主备,一个Set有多台机器,过载机器的请求被分摊到多台机器,容灾效果会更好。在seqsvr中使用类似一致性Hash的容灾策略也是可行的,只要Client端与仲裁服务都使用完全一样的一致性Hash算法,这样Client端可以启发式地去尝试,直到找到正确的AllocSvr。
例如对于某个uid,仲裁服务会优先把它分配到AllocSvrA,如果AllocSvrA挂掉则分配到AllocSvrB,再不行分配到AllocSvrC。那么Client在访问AllocSvr时,按照AllocSvrA -> AllocSvrB -> AllocSvrC的顺序去访问,也能实现容灾的目的。但这种方法仍然没有克服前面主备容灾面临的配置文件变更的问题,运营起来也很麻烦。
最后我们另辟蹊径,采用了一种不同的思路:既然Client端与AllocSvr存在路由状态不一致的问题,那么让AllocSvr把当前的路由状态传递给Client端,打破之前只能根据本地Client配置文件做路由决策的限制,从根本上解决这个问题。
所以在2.0架构中,我们把AllocSvr的路由状态嵌入到Client请求sequence的响应包中,在不带来额外的资源消耗的情况下,实现了Client端与AllocSvr之间的路由状态一致。具体实现方案如下:
seqsvr所有模块使用了统一的路由表,描述了uid号段到AllocSvr的全映射。这份路由表由仲裁服务根据AllocSvr的服务状态生成,写到StoreSvr中,由AllocSvr当作租约读出,最后在业务返回包里旁路给Client端。
把路由表嵌入到取sequence的请求响应包中,那么会引入一个类似“先有鸡还是先有蛋”的哲学命题:没有路由表,怎么知道去哪台AllocSvr取路由表?另外,取sequence是一个超高频的请求,如何避免嵌入路由表带来的带宽消耗?
这里通过在Client端内存缓存路由表以及路由版本号来解决,请求步骤如下:
基于以上的请求步骤,在本地路由表失效的时候,使用少量的重试便可以拉到正确的路由,正常提供服务。
到此把seqsvr的架构设计和演变基本讲完了,正是如此简单优雅的模型,为微信的其它模块提供了一种简单可靠的一致性解决方案,支撑着微信五年来的高速发展,相信在可预见的未来仍然会发挥着重要的作用。
? 本文系 微信后台团队 ,如有侵犯,请联系我们立即删除
我们的官网及论坛:? OpenIM官网
OpenIM官方论坛
红色警戒3命令与征服 联机 cd key重复怎么办
没有正则一、CPU都有一个唯一的ID号,称CPUID,是在制造CPU的时候,由厂家置入到CPU内部的。
二、查看方法:
1、右点开始,选运行,并输入CMD。
2、输入wmic CPU get ProcessorID ,就可以得到ID。
三、作用和意义:
由于CPU外在的所有标记、符号,都是可以人为打磨,而CPUID却是终身不变的,只能用软件读出ID号;因此,利用这个原理,CPU ID工具可以显出CPU的确切信息,包括移动版本、主频、外频、二级缓存等关键信息,从而查出超频的CPU,并且醒目地显示出来。
cd key重复必须修改cd key ,方法如下:
在游戏文件夹里找注册表修复+序列号切换+语言切换器,生成并切换一下序列号即可。
用cdkey算出新的cdkey,把算出来的cdkey删除中间的连接符也就是"-",然后打开附件注册表信息,方法是在文件上单击鼠标右键出现编辑,把算出的去横杠的cdkey复制粘贴在引号里面。然后保存退出,导入注册表信息即可。
好了,关于“序列号生成器有用吗”的话题就到这里了。希望大家通过我的介绍对“序列号生成器有用吗”有更全面、深入的认识,并且能够在今后的实践中更好地运用所学知识。
上一篇:小米2s手机序列号查询
下一篇:小米笔记本如何进入bios界面